Attentions 查缺补漏
Loung的Attention paper: https://arxiv.org/abs/1508.04025
Bahdanau的Attention Paper: https://arxiv.org/abs/1409.0473
首先,啥是attention:
拿输入-输出的双向互Loung attention来说,它就是一个输入段各个token,对应输出端各个token的相关系数,输入端经过lstm编码,变成一系列hidden vectors \(h_t\),每一个这些\(h_t\)对应输出端当前的hidden vector都有一个对应系数,也就是某个输入段的hidden vector与输出端当前hidden vector的相关系数,也就是attention的值a
其次,怎么计算attention:
这里涉及到Loung和Bahdanau的attention计算方法不同了,Loung是用encoder最上边的一层lstm的所有hidden vector来计算互相关系数,Bahdanau是用所有lstm层的hidden vector和输出端的\(h_{t-1}\) concatenate起来计算。
attention是一个经过softmax之后的权重值,在经过softmax之前它叫作score(Loung)或energy(Bahdanau),这个score按照Loung来说是这三种其一:
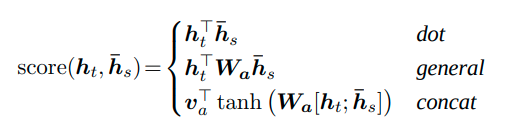
Bahdanau的Attention只有concatenation的那个(注意这里还没有出现\(\sqrt{d}\)归一化,这玩意是在transformer里面的)
最后,怎么使用attention
把attention的a值当作一个权重,同input的hidden states点乘,得一个加权平均。这个加权平均是contextector,在Loung里面contex vector直接和输出端的hidden state concatenate,然后全链接,然后softmax预测输出,而在Bahdanau里面,在得到输出端的hidden state之后还需要再和context一起进行一个g的运算,才能得到最终prediction